
- 9
- 1 079 691
Ari Seff
Приєднався 23 вер 2011
I'm a research scientist at Apple. Previously I developed models for simulation and planning at Waymo and completed a PhD at Princeton in machine learning. I’m using this channel to make short tutorials about various ML or related math topics. Stay tuned for new videos!
Why Can’t Language Models Learn to Speak Backwards?
Language models can't learn as well in reverse? In this video, we look at the paper "Arrows of Time for Large Language Models" which studies this phenomenon and offers some theories to explain it.
Paper: arxiv.org/abs/2401.17505
Timestamps:
0:00 - Sequential prediction in language models
0:43 - Does order matter?
1:42 - Forwards and backwards factorizations
2:47 - Loss
3:44 - Results on different languages
4:57 - Ablation: Context window size
5:44 - Ablation: Model size
6:06 - Toy experiment: Prime factorization
8:28 - Linear languages
9:58 - Thought experiment
10:57 - Open questions
Paper: arxiv.org/abs/2401.17505
Timestamps:
0:00 - Sequential prediction in language models
0:43 - Does order matter?
1:42 - Forwards and backwards factorizations
2:47 - Loss
3:44 - Results on different languages
4:57 - Ablation: Context window size
5:44 - Ablation: Model size
6:06 - Toy experiment: Prime factorization
8:28 - Linear languages
9:58 - Thought experiment
10:57 - Open questions
Переглядів: 2 336
Відео


How ChatGPT is Trained
Переглядів 518 тис.Рік тому
This short tutorial explains the training objectives used to develop ChatGPT, the new chatbot language model from OpenAI. Timestamps: 0:00 - Non-intro 0:24 - Training overview 1:33 - Generative pretraining (the raw language model) 4:18 - The alignment problem 6:26 - Supervised fine-tuning 7:19 - Limitations of supervision: distributional shift 8:50 - Reward learning based on preferences 10:39 -...

What are Diffusion Models?
Переглядів 206 тис.2 роки тому
This short tutorial covers the basics of diffusion models, a simple yet expressive approach to generative modeling. They've been behind a recent string of impressive results, including OpenAI's DALL-E 2, Google's Imagen, and Stable Diffusion. Errata: At 12:39, parentheses are missing around the difference: \epsilon(x, t, y) - \epsilon(x, t, \empty). See i.imgur.com/PhUxugm.png for corrected ver...
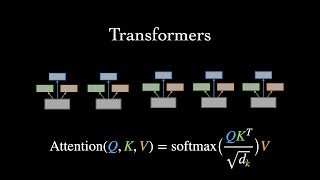
What are Transformer Neural Networks?
Переглядів 160 тис.3 роки тому
This short tutorial covers the basics of the Transformer, a neural network architecture designed for handling sequential data in machine learning. Timestamps: 0:00 - Intro 1:18 - Motivation for developing the Transformer 2:44 - Input embeddings (start of encoder walk-through) 3:29 - Attention 6:29 - Multi-head attention 7:55 - Positional encodings 9:59 - Add & norm, feedforward, & stacking enco...

Why Do Random Walks Get Lost in 3D?
Переглядів 16 тис.3 роки тому
In this video, we try to gain some intuition for why symmetric random walks are recurrent in 1 and 2D, but transient in 3D. This was proved by mathematician George Pólya in 1921. Links for further reading: Awesome demos of random walks by Russell Lyons (rdlyons.pages.iu.edu/rw/rw.html) Analysis of high-dimensional random walks by Gregory Lawler, including expected escape time (www.math.uchicago...
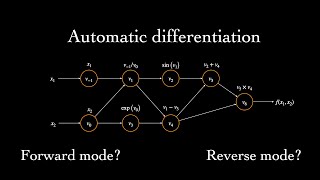
What is Automatic Differentiation?
Переглядів 104 тис.3 роки тому
This short tutorial covers the basics of automatic differentiation, a set of techniques that allow us to efficiently compute derivatives of functions implemented as programs. It is based in part on Baydin et al., 2018: Automatic Differentiation in Machine Learning: A Survey (arxiv.org/abs/1502.05767). Errata: At 6:23 in bottom right, it should be v̇6 = v̇5*v4 v̇4*v5 (instead of "-"). Additional...

What are Normalizing Flows?
Переглядів 68 тис.4 роки тому
This short tutorial covers the basics of normalizing flows, a technique used in machine learning to build up complex probability distributions by transforming simple ones. Timestamps: 0:00 - Intro 0:33 - Bijective transformation 1:18 - Change of variables formula 2:08 - Jacobian determinant 4:28 - Generative model likelihood 5:49 - Comparison with VAEs & GANs 6:52 - NICE architecture: triangula...

Autonomous U-turns with Direct Perception
Переглядів 3,4 тис.7 років тому
An extension of DeepDriving (deepdriving.cs.princeton.edu) for two-way traffic with U-turns. The host car can have one of two goals at any moment: either continue ahead in the current direction of travel or make the the next available U-turn. The host car's "goal" is analogous to a navigation system providing directions (e.g., make the next right, take the next exit). To gather training data fo...
For an ML application, why is it that O(ops(f)) time for automatic diff is considered a faster runtime than O(n) for numerical diff - it seems to me as though the # inputs should be a lower bound for how many operations there are between those inputs .... if this is the case then why use automatic diff at all for ML?
one thing i don't understand is why can't forward pass do it for multiple input variables? is there a limitation im unaware of?
Can you do a video about image denoising using wavelet transforms
Reverse-on-Forward sounds like ACA.
By far best explanation of diffusion models
I have question about this fragment 06:58. Im not sure but I suppose that R dimensionality schould be d_k*D not D*d_k
Just as a note for anyone wondering, the arxiv link doesn't work because it includes the closing parenthesis. Otherwise great video!
great great great , Thanks a million 😃
Hands down the best intro to gen models one could ever had.
Great video! Where can I learn more about the rounding and truncation errors plot at 2:06? I need to make an analysis of these errors for a project. Thanks :)
Amazing
Are the animations and sound track inspired from a channel named 3Blue1Brown ?
you are amazing at explaining this concept in such a simple and understandable manner mate
I've been toying with this idea for while. It would be great to have a language model to which you could give an answer as prompt and it would output the deduction to that answer going in reverse. My wild guess is that the domain of things that can lead to something is greater than the domain of things that are the outcome of a group of things. All roads lead to Rome. Causality?
Wonderful video. The detailed example helps tremendously. And I think there's an error: At t=6.24, sInce $v_6 = v_5\times v_4$, in $\dot{v}_6$ shouldn't there be a plus sign where you've got a minus sign?
Very much valuable content explained with clarity I wonder why you channel haven't still exploded you earned a new sub and continue making videos on such topics
Fantastic explanation!
Shingle Magic better than RoofMaxx
I'm not fully sure what you mean by learning backwards in the context of this video, but if I'm understanding this correctly, my guess is that some languages that contain conjugations at the end of the word (or suffixes) makes language learning asymmetric. Because of that, when programmers try to tokenize the text, it's easier to say "ing" comes after "learn" (predicting forward) instead of saying "learn" comes before "ing" (predicting backwards). That being said, it's obvious that there are many root words that come before "ing." On the contrary, there are only so many possibilities that come after "learn". These are one of the asymetries of the semantic sequencing behind latin languages, and since Transformers learns and predicts from one end to another, this seems like a real possibility of why GPTs act like this. I also took a quick glance into the paper and saw that they did address tokenization, but I'm not sure if the method that they used addresses what I'm saying correctly.
This explanation is not correct. It is indeed more likely that 'ing' comes after 'learn' than to have 'learn' come before 'ing'; however, if you take into account the probability of seeing 'ing' at the end of a word, it is higher than that of seeing 'learn' at the beginning of the word; if you compute the probabilities one way or another, you will get exactly the same. So it's not about the probabilities in a language being higher one way or another (they are *exactly the same*, when multiplying the conditional probabilities), it's about them being harder to learn (or to compute). Also, this appears to not be so much related to the syntactic structure of the language, as the effect is universal across languages and is mostly apparent when the context window size gets large (at which scale the orders of the words in a sentence become less relevant, since it is at the scale of quite a few sentences)
@@mesdamessoleils9869 I'm not quite sure how you computed the probabilities or why you even used that example to get the point across as it might not even be relevant to how a transformer works. Just curious though, how much experience do you have with knowing how transformers work inside out? I myself just learned recently and not 100% clear, nor am not sure of the model or the exact way they did it exactly, but if I have access to the source code, would probably be able to figure this out (rather just theories). However, judging by what I know, the model is trains and predicts a token based on the previous tokens passed into it. So even if I know that at the end of the word, "ing" happens more at the end of the word, I still would have more trouble predicting the root word ("learn" ) behind it rather than predicting "ing" comes after "learn". Just imagine it in terms of possible branches. Obviously, the more choices of likely words to choose from, the less probability for you to predict the next word correctly. Lets say make an example sentence, "I like learning math from my teacher" and the standard tokens are probably "I", "like", "learn", "ing", "math", "from", "my", "teacher". Moreover, assume that the model is trained with a bit more grammatically correct examples. Once my model generates up to the point, "I like learn", the next possible token that makes grammatically correct is easily going to be "ing" or something of high affinity if I use a different example. However, training it backwards, if I predicted "math from my teacher," I'm split between whether I should use a suffix ("ing") or ("learn") because each of them sounds grammatically plausible. Predicting backwards on a larger trained model, I can reasonably get the sentence "I like to learn math from my teacher" or "I like learning math from my teacher". As you can see, there are two plausible options predicting backwards which basically splits the probability of a confident prediction in two while going forwards, it most definitely is easier to complete the puzzle simply following the context clues (which GPTs are basically made for). I might not have exhausted all the cases, but you can probably see what I mean now. From that stand point, it's generally easier to predict forwards than backwards as you can see with english, and you can see this even more when you look at the syntactic structure of English. Generally speaking, we can predict that a good deal of english sentences start with a noun (aka subject or pronouns such as "I") while english sentences can end in a plethora of ways (nouns, verbs, words with suffixes which acts as a token of its own), making the amount of plausible choices that much more when trying to predict backwards. This mass of choices lowers the probability (aka certainty) that we have a confident right answer, hence unequal probabilities forward and back. Moreover, I think the video pretty much is mentioning what I am mentioning through various abstract examples, such as timestamp 6:36 for example. He pretty much says that it's much harder to predict the factors of a product rather than predict the product from the two factors, which completely makes sense. In essence, the models are struggling to learn backwards probably IS in fact since it's harder to learn/solve backwards, and the metric that shows that is the unequal joint probabilities of the sentence forward and back. I looked into the paper and video and found that the loss difference IS infact calculated by the joint probabilities instead, yet they are not the same. Moreover, the conditional probabilities are definitely most likely different forward and back given they are completely different conditional probabilities (NOT EQUAL) and likely behaved in the way I mentioned it. As for the context size affecting the learning difference, I believe the smaller context size (as mentioned in the video) spits out garbage predictions forward and back equally terribly, making the loss equally bad in either direction. However, increasing the context size allows the model to understand the context a lot more and hit more roadbumps along the way, possibly adding up the bigger disparity between the losses/probabilities. I wished they tested out more languages before claiming it's universal, as we might find a language that is easier to learn backwards than forward, but I don't remember a language with a sentence structure unique enough to do so.
@@mesdamessoleils9869 I'm not quite sure how you computed the probabilities or why you even used that example to get the point across as it might not even be relevant to how a transformer works. Just curious though, how much experience do you have with knowing how transformers work inside out? I myself just learned recently and not 100% clear, nor am not sure of the model or the exact way they did it exactly, but if I have access to the source code, would probably be able to figure this out (rather just theories). However, judging by what I know, the model is trains and predicts a token based on the previous tokens passed into it. So even if I know that at the end of the word, "ing" happens more at the end of the word, I still would have more trouble predicting the root word ("learn" ) behind it rather than predicting "ing" comes after "learn". Just imagine it in terms of possible branches. Obviously, the more choices of likely words to choose from, the less probability for you to predict the next word correctly. Lets say make an example sentence, "I like learning math from my teacher" and the standard tokens are probably "I", "like", "learn", "ing", "math", "from", "my", "teacher". Moreover, assume that the model is trained with a bit more grammatically correct examples. Once my model generates up to the point, "I like learn", the next possible token that makes grammatically correct is easily going to be "ing" or something of high affinity if I use a different example. However, training it backwards, if I predicted "math from my teacher," I'm split between whether I should use a suffix ("ing") or ("learn") because each of them sounds grammatically plausible. Predicting backwards on a larger trained model, I can reasonably get the sentence "I like to learn math from my teacher" or "I like learning math from my teacher". As you can see, there are two plausible options predicting backwards which basically splits the probability of a confident prediction in two while going forwards, it most definitely is easier to complete the puzzle simply following the context clues (which GPTs are basically made for). I might not have exhausted all the cases, but you can probably see what I mean now. From that stand point, it's generally easier to predict forwards than backwards as you can see with english, and you can see this even more when you look at the syntactic structure of English. Generally speaking, we can predict that a good deal of english sentences start with a noun (aka subject or pronouns such as "I") while english sentences can end in a plethora of ways (nouns, verbs, words with suffixes which acts as a token of its own), making the amount of plausible choices that much more when trying to predict backwards. This mass of choices lowers the probability (aka certainty) that we have a confident right answer, hence unequal probabilities forward and back. Moreover, I think the video pretty much is mentioning what I am mentioning through various abstract examples, such as timestamp 6:36 for example. He pretty much says that it's much harder to predict the factors of a product rather than predict the product from the two factors, which completely makes sense. In essence, the models are struggling to learn backwards probably IS in fact since it's harder to learn/solve backwards, and the metric that shows that is the unequal joint probabilities of the sentence forward and back. I looked into the paper and video and found that the loss difference IS infact calculated by the joint probabilities instead, yet they are not the same. Moreover, the conditional probabilities are definitely most likely different forward and back given they are completely different conditional probabilities (NOT EQUAL) and likely behaved in the way I mentioned it. As for the context size affecting the learning difference, I believe the smaller context size (as mentioned in the video) spits out garbage predictions forward and back equally terribly, making the loss equally bad in either direction. However, increasing the context size allows the model to understand the context a lot more and hit more roadbumps along the way, possibly adding up the bigger disparity between the losses/probabilities. I wished they tested out more languages before claiming it's universal, as we might find a language that is easier to learn backwards than forward, but I don't remember a language with a sentence structure unique enough to do so.
@@mesdamessoleils9869 I'm not quite sure how you computed the probabilities or why you even used that example to get the point across as it might not even be relevant to how a transformer works. Just curious though, how much experience do you have with knowing how transformers work inside out? I myself just learned recently and not 100% clear, nor am not sure of the model or the exact way they did it exactly, but if I have access to the source code, would probably be able to figure this out (rather just theories). However, judging by what I know, the model is trains and predicts a token based on the previous tokens passed into it. So even if I know that at the end of the word, "ing" happens more at the end of the word, I still would have more trouble predicting the root word ("learn" ) behind it rather than predicting "ing" comes after "learn". Just imagine it in terms of possible branches. Obviously, the more choices of likely words to choose from, the less probability for you to predict the next word correctly. Lets say make an example sentence, "I like learning math from my teacher" and the standard tokens are probably "I", "like", "learn", "ing", "math", "from", "my", "teacher". Moreover, assume that the model is trained with a bit more grammatically correct examples. Once my model generates up to the point, "I like learn", the next possible token that makes grammatically correct is easily going to be "ing" or something of high affinity if I use a different example. However, training it backwards, if I predicted "math from my teacher," I'm split between whether I should use a suffix ("ing") or ("learn") because each of them sounds grammatically plausible. Predicting backwards on a larger trained model, I can reasonably get the sentence "I like to learn math from my teacher" or "I like learning math from my teacher". As you can see, there are two plausible options predicting backwards which basically splits the probability of a confident prediction in two while going forwards, it most definitely is easier to complete the puzzle simply following the context clues (which GPTs are basically made for). I might not have exhausted all the cases, but you can probably see what I mean now. From that stand point, it's generally easier to predict forwards than backwards as you can see with english, and you can see this even more when you look at the syntactic structure of English. Generally speaking, we can predict that a good deal of english sentences start with a noun (aka subject or pronouns such as "I") while english sentences can end in a plethora of ways (nouns, verbs, words with suffixes which acts as a token of its own), making the amount of plausible choices that much more when trying to predict backwards. This mass of choices lowers the probability (aka certainty) that we have a confident right answer, hence unequal probabilities forward and back. Moreover, I think the video pretty much is mentioning what I am mentioning through various abstract examples, such as timestamp 6:36 for example. He pretty much says that it's much harder to predict the factors of a product rather than predict the product from the two factors, which completely makes sense. In essence, the models are struggling to learn backwards probably IS in fact since it's harder to learn/solve backwards, and the metric that shows that is the unequal joint probabilities of the sentence forward and back. I looked into the paper and video and found that the loss difference IS infact calculated by the joint probabilities instead, yet they are not the same. Moreover, the conditional probabilities are definitely most likely different forward and back given they are completely different conditional probabilities (NOT EQUAL) and likely behaved in the way I mentioned it. As for the context size affecting the learning difference, I believe the smaller context size (as mentioned in the video) spits out garbage predictions forward and back equally terribly, making the loss equally bad in either direction. However, increasing the context size allows the model to understand the context a lot more and hit more roadbumps along the way, possibly adding up the bigger disparity between the losses/probabilities. I wished they tested out more languages before claiming it's universal, as we might find a language that is easier to learn backwards than forward, but I don't remember a language with a sentence structure unique enough to do so.
@@mesdamessoleils9869 I'm not quite sure how you computed the probabilities or why you even used that example to get the point across as it might not even be relevant to how a transformer works. Just curious though, how much experience do you have with knowing how transformers work inside out? I myself just learned recently and not 100% clear, nor am not sure of the model or the exact way they did it exactly, but if I have access to the source code, would probably be able to figure this out (rather just theories). However, judging by what I know, the model is trains and predicts a token based on the previous tokens passed into it. So even if I know that at the end of the word, "ing" happens more at the end of the word, I still would have more trouble predicting the root word ("learn" ) behind it rather than predicting "ing" comes after "learn". Just imagine it in terms of possible branches. Obviously, the more choices of likely words to choose from, the less probability for you to predict the next word correctly. Lets say make an example sentence, "I like learning math from my teacher" and the standard tokens are probably "I", "like", "learn", "ing", "math", "from", "my", "teacher". Moreover, assume that the model is trained with a bit more grammatically correct examples. Once my model generates up to the point, "I like learn", the next possible token that makes grammatically correct is easily going to be "ing" or something of high affinity if I use a different example. However, training it backwards, if I predicted "math from my teacher," I'm split between whether I should use a suffix ("ing") or ("learn") because each of them sounds grammatically plausible. Predicting backwards on a larger trained model, I can reasonably get the sentence "I like to learn math from my teacher" or "I like learning math from my teacher". As you can see, there are two plausible options predicting backwards which basically splits the probability of a confident prediction in two while going forwards, it most definitely is easier to complete the puzzle simply following the context clues (which GPTs are basically made for). I might not have exhausted all the cases, but you can probably see what I mean now. From that stand point, it's generally easier to predict forwards than backwards as you can see with english, and you can see this even more when you look at the syntactic structure of English. Generally speaking, we can predict that a good deal of english sentences start with a noun (aka subject or pronouns such as "I") while english sentences can end in a plethora of ways (nouns, verbs, words with suffixes which acts as a token of its own), making the amount of plausible choices that much more when trying to predict backwards. This mass of choices lowers the probability (aka certainty) that we have a confident right answer, hence unequal probabilities forward and back. Moreover, I think the video pretty much is mentioning what I am mentioning through various abstract examples, such as timestamp 6:36 for example. He pretty much says that it's much harder to predict the factors of a product rather than predict the product from the two factors, which completely makes sense. In essence, the models are struggling to learn backwards probably IS in fact since it's harder to learn/solve backwards, and the metric that shows that is the unequal joint probabilities of the sentence forward and back. I looked into the paper and video and found that the loss difference IS infact calculated by the joint probabilities instead, yet they are not the same. Moreover, the conditional probabilities are definitely most likely different forward and back given they are completely different conditional probabilities (NOT EQUAL) and likely behaved in the way I mentioned it. As for the context size affecting the learning difference, I believe the smaller context size (as mentioned in the video) spits out garbage predictions forward and back equally terribly, making the loss equally bad in either direction. However, increasing the context size allows the model to understand the context a lot more and hit more roadbumps along the way, possibly adding up the bigger disparity between the losses/probabilities. I wished they tested out more languages before claiming it's universal, as we might find a language that is easier to learn backwards than forward, but I don't remember a language with a sentence structure unique enough to do so.
Great job. Going to show this to my class (Large Language Models for Lawyers, University of Houston Law Center)
Nicely explained, thanks
This is really interesting. I also assumed you've just got a map and it doesn't matter what order you learn it in. But I guess the sequence is important, a model that learns in a forward order is aligned with both 1) sentences making sense to a listener due to previous info, and 2) learning how to generate sequences that exists in a system of thinking in words, forwards in time. Both of those are things to do with human brains likely have optimizations that facilitate better sentence constuction and understanding, so a model learning that way would just have a natural alignment. Video frames generated backwards are likely a mathematically identical problem but perceptually different for similar reasons. Going from a broken glass all over the floor to an intact glass in an implausible location is noticeable, an intact glass going to broken glass in odd locations is not. They both might be the same hard problem, but the forwards condition is much easier to fake; if you start with something constrained then things can fan out naturally. I guess rather than 20/20 and blind, hindsight is something like `sight/(hind^2)` while foresight is something like `sight/fore!`, and if you flip that round you have the problem in the other direction as the distance and number of insights increase.
Nice explanation!
Hello everyone from 2024, it seems the flow-matching hype has begun
I also feel the residual connection is definitely RNN inspired.
@Ari, this is really great! 🤩🤩🤩
Thanks Alfredo!
giving my 3blue1brown vibes. Amazing video.
great video imagery... good job. Love seeing the flow of information, and little opinions about why things are happening. got a bit confusing when it went away from images to just pure equations, could do images and boxes with the equations?
Glad your back!
There’s an argument that all spoken human languages convey information (in the, like, Shannon sense) at the same rate. If this is roughly true, you can take the words per minute average for a spoken language, and use it as a proxy for information per word. According to my googling, spoken French averages more words per minute than English, so this implies that English may convey more information per word. Then, more salient pieces of information in a block of text would be spread over more tokens in French than in English. Therefore, we would expect sequence reversal to impede French more dramatically than English, since English words contain more intrinsic information which is then shielded from reversal. Have the authors (or anyone else) explored this angle, and does it hold up for other languages?
Very nice connection. I wonder how tokenization would affect this analysis. According to Sec. 2.1.1, the authors train a BPE tokenizer from scratch for each language individually. So even if French has a higher rate of spoken words per minute than English, perhaps the relevant statistic here would be "tokens per minute", since the reversal happens at the token level. For example, if it were the case that tokens per minute for the two languages ends up being similar, this would weaken this theory. These details are not examined in the paper but would definitely be interesting to see!
@@ariseffai Good point! I guess the average number of tokens per word is going to come down to how long French words tend to be compared to English words, and how repetitive the character combinations are, since they used the same total number of tokens when encoding both languages. Could definitely cancel out this effect, or even be the dominant cause of the difference itself!
Try Sanskrit
Please hear me out : Language can reduce entropy by an infinite amount, when we say "table" we convey the idea of a legged object with a planar surface that can hold things, with an infinite amount of variations of any of its components yet we all recognize the object when we see it. This way of communication reduces uncertainty "forward" by the infinite amount of variations that it can hold. But which one of the variations that the concept contains is "backward"?
I think it's interesting that they limited themselves to reversible mappings in the formal languages section. In classical thermodynamics the arrow of time comes from the observables carrying less information about the exact micro state and only the micro states follow reversible predictions. If we want to create an analogy to thermodynamics, the words and sentences of a language would the observables of the complex act of communication, with only the entire system (including my thought, goals etc) following a reversible time evolution. But that still leaves the question: why would average information of a specific microstate given a macrostate increase in natural language? There are some example where that seems obvious, a joke setup probably implies the punchline, but not vice versa, same for the proof of a theorem. But it's just as easy to find examples in the opposite direction, the last chapter of a detective novel probably predicts the entirety of it better than vice verse.
Thank you for a very clear expansion of the paper! But I'm not convinced by the paper itself. After recent watching of Andrej's Karpathy's tutorial on Tokenizer IMO its expected to see that when you take a highly tuned system, and significantly change one part, you expect the performance to drop because the other pieces are no longer as tuned for that task. IMO here the paper would be more convincing if it was trained on chars with no tokenizer. Than on "forward" tokens in reverse.
We tried that as well ! For one dataset, we trained the BPE tokenizer backwards, then made the experiment again with this tokenizer; If the asymmetry came from the tokenizer, you would expect the backward model to now do better; but it doesn't ! In fact, the loss curves for the 'reverse BPE' and 'forward BPE' tokenizers look almost identical. This means the arrow of time effect is not a result of the way you tokenize, but really a feature of the dataset. (BTW, we thought about char tokenizers, problem is with those it's very costly to train models with attention spanning more than a few sentences; since in that case a sentence is already 100s of tokens, and compute scales quadratically with attention)
Ari , you have an incredible ability to explain stuff.
Thanks! Appreciate the kind words.
why reverse the tokens instead of reversing words? or even letters to make new tokens
I work with proteins - and they are very interesting because they have a linear sequential structure and a very complex 3d relations after folding. It is getting obvious that not all structures of information can be learned via GPT. But I suppose we will just see more adaptors like in "let my graph do the talking" or omnifusion for new data modalities. Although on a second thought even though we have a mostly linear dependency in text - we think more sparatically. May be we will se other architectures as "thought hubs". Reminds me alot about "Arrival"
best AI tutorial of the year🔥
r u 4 r3aL?
Not quite sure about that haha
My guess is that in video prediction it would depend a lot on the video for example the video of a ball being thrown around or a pendulum is easily predictable even when time is reversed but think about a video of bob ross and you watch it backwards as he unmixes color. A good guess is probably that the mixed some color with white but unmixing two colors is extremely hard to predict.
Neat. Although one might also argue it should be easier in reverse because you can assume you will eventually reach a blank white canvas at the beginning of the video. But going forward, when you start with the blank white canvas, it is difficult to predict the exact scene that will be painted :)
It feels obvious. Language has a lot of structure that back-reference like pronouns and stuff which are straight forward in one direction but practically impossible to reverse.
Interesting! For me it was not a priori obvious. I like the sparsity argument from the paper as a potential mechanism, but I'd love to see concretely how one can prove language is "sparser" in the forward direction. The pronoun example has potential, but as @grapesurgeon mentions, there can often be forward references as well.
@@grapesurgeon (Almost) all natural languages developed as a spoken language. It's much harder for the brain to build sentences that reference something that you will say three sentences later, because it would require you to already "build" the next three sentences in your head while you say the current sentence. Let's assume you currently "build" and say sentence A and next are B, C, D, etc. for A to reference B and C you'd also have them ready in your brain and thus B and C can't reference D, E, F or they would also influence how A is structured. There are some "high level" thoughts that do that, like "I'll tell you the details about that later..." but to say that you don't have to know the exact sentences you'll say later. But language itself (at least it feels obvious to me - I can't back any of that up) look like it has to have that structure and I assume even for advanced super human intelligence but probably with a larger time-frame/window. I think it boils down to that predicting the future is harder than storing/remembering the past. So it's simpler to reference something from the "exact" past than to reference something from the "exact" future because it's so hard to predict the "exact" future.
We turn off the music when we talk
I think the way you explained the probability relationships is a bit poor. For example p_t(x) = p_t(f_t^(-1)(x)) would imply the obvious desire for f_t to be the identity map. If x is a different r.v. then there is no reason one would make such a claim. The entire point is that the rv's may have different probabilities due to the map(and it may not even be injective) and so one has to scale the rv's probabilities which is where the jacobian comes in(as would a sum over the different branches). It would have been better to start with two different rv's and show how one could transform one in to another and the issues that might creep. E.g., This is how one would normally try to solve the problem from first principles. The way you set it up leaves a lot to be desired. E.g., while two rv's can easily take the same value they can have totally different probabilities which is the entire point of comparing them in this way. I don't know who would start off thinking two arbitrary rv's would have the same probabilities and sorta implying that then saying "oh wait, sike!" isn't really a good way to teach it.
Extremely good video, not shying away from the math. More like this is needed.
as a beginner i understood nothing. change the title because these are not the basics
Great video!
Sounds like a legal document "which are implemented as linear transformations of the embeddings" - yeah, thanks a lot. Now, back to your autists special needs class.
It's uses diffusion model..... search it up, you would then realize why it can't inspect images
what are you even talking about?
Great work really, there is a mistake in the equation on the rightmost side at 12:46.
Great video, thank you! Just a question, you said a main problem with symbolic differentiation is that no control flow operations can be part of the function. Is that in any way different for Automatic differentiation?
king
Why do we sum the positional and input embeddings? Wouldnt concatenating make more sense? How would that play with dimensions?